
Chinese team investigates LLMs to help stroke victims speak
Came across this the other day.
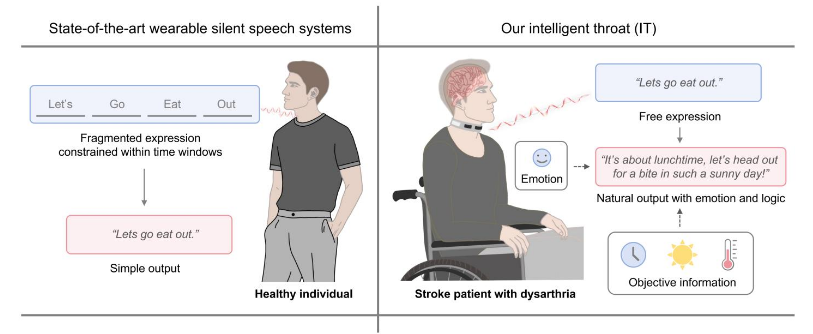
A new paper released on the 19th of January, the multinational team investigates the potential for LLM models combined with real time bio-metric information to help stroke victims suffering from Dysarthria (a disorder where the muscles we use to speak have been paralyzed or compromised in some way) communicate again.
Dysarthia is a common symptom of things like strokes, traumatic brain injuries or brain tumours. Anything that damages the ability of the brain to control the muscles around our lips, tongue, larynx and so on. Combine that with other neuroligical conditions such as Aphasia (in which the language part of the brain gets scrambled) and it can be incredibly distressing for the individuals concerned.
For this paper, the team was looking at a way to give people back the ability to communicate – without surgery – in as natural a way as is possible, including taking emotional state into account.
To do this, they built the Intelligent Throat (or IT).
Yeah, that’s what they called it.
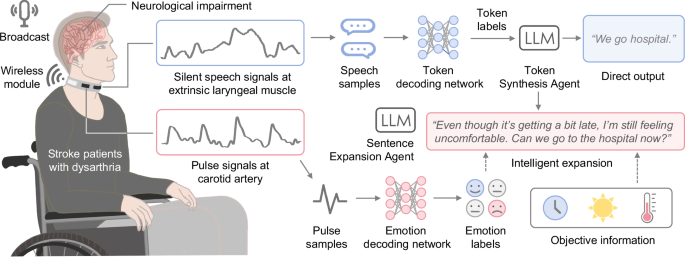
Physically the IT is made of up the following:
- A Printed Circuit Board with the software loaded on it.
- A choker like band that goes around the throat.
- Sensors to detect both sub vocalization AND the current heart rate of the user
The way it works is
- The user sub vocalises what they can
- The first of two AI Agents takes the words, and using OpenAIs GPT-4o-mini API infers the meaning of the words.
- A second AI Agent then takes that inference and tries to work out the emotional state of the user so that it can give the result the correct tone.
- The final phrase or sentence is then sent to a read out device
The paper details how they built the device and the source code is also available for anyone to pick up here https://github.com/tcy21414/Intelligent-Throat
While they reported increased user satisfaction with the device, the study was pretty small (10 healthy people and 5 people with Dysarthia). There are a number of questions that I think need to be addressed in any future studies. Here’s a few
- At what level of impairment is the device best used?
- Can we used embedded systems instead of the API? Needing the internet to communicate isn’t great
- Language support, as I understand it, this study was conducted in Mandarin (the study participants were Chinese). How well do certain languages work with systems like this?
- Can you swear with it?
